Predictive Sales Analytics mit Excel? Es würde gehen!

Wohin dürfen wir das PDF senden?
Anwendungsbeispiele von Predictive (Sales) Analytics Methoden für die Vertriebsplanung mit einer Excel Vorlage.
Eine der wichtigsten Aufgaben eines Vertriebsleiters ist es rechtzeitig zu erkennen, hinter welchen Verkaufschancen gute Möglichkeiten stehen. Diese Aufgabe zu erfüllen, ist das A und O einer erfolgreichen Vertriebsplanung.
Key Account Manager im B2B-Bereich bedienen in der Regel Hunderte von Kunden und überwachen Dutzende von neuen und bestehenden Verkaufsmöglichkeiten (oder Opportunities). Sie haben nur begrenzte Zeit und sind eine der teuersten Ressourcen in einem Unternehmen.
Um vereinbarte Verkaufsziele zu erreichen, ist es daher wichtig zu wissen, wo Prioritäten gesetzt werden müssen. Soll ich Kunden A erneut kontaktieren oder lieber Kunden B? Sollten wir aufhören, eine Verkaufschance zu verfolgen? Erfahrene Vertriebsleute wissen, dass es für eine gute Arbeit unerlässlich ist, die richtigen Prioritäten zu setzen.
Nehmen Sie nun an, dass ein Vertriebsmitarbeiter im Voraus feststellen kann, welche Merkmale Ihre erfolgreichsten Leads, Opportunities oder Verkaufsanfragen haben. In purer Marketingsprache würden wir von „Lead Scoring“ sprechen. Im B2B-Vertrieb sprechen wir von einer effizienten Vertriebsplanung.
Predictive Analytics Beispiel mit Excel. So sieht es im B2B-Vertrieb aus.
Lassen Sie uns hier ein einfaches Predictive Analytics Model mit Excel erstellen. Wir wollen eine Gruppe von Elementen (die Opportunities) in Bezug auf ihre Erfolgschancen aufteilen. Im Data Mining Bereich, würden wir dieses Problem als „überwachte Segmentierung“ definieren (auf Englisch Supervised Segmentation).
Überwachte Segmentierung ist ein grundlegendes Konzept des Data Mining. Stellen Sie sich vor, ein Vertriebsleiter muss herausfinden, welche „Attribute“ oder Merkmale eine erfolgreiche Verkaufschance oder Lead haben. Mit anderen Worten versucht er, die Eigenschaften zu ermitteln, die mehr Informationen über eine Verkaufschance bieten.
Das folgende Bild zeigt ein typisches Beispiel für eine Liste von offenen Verkaufsanfragen, Verkaufschancen oder Leads mit MS Excel. Es enthält vergangene Leads und ob das Vertriebsteam sie akquiriert oder verloren hat. Die meisten Vertriebsteams in Business-to-Business arbeiten auf eine ähnliche Weise. In maschineller Lernen Terminologie repräsentiert diese Liste Ihre „Trainings“ -Daten.
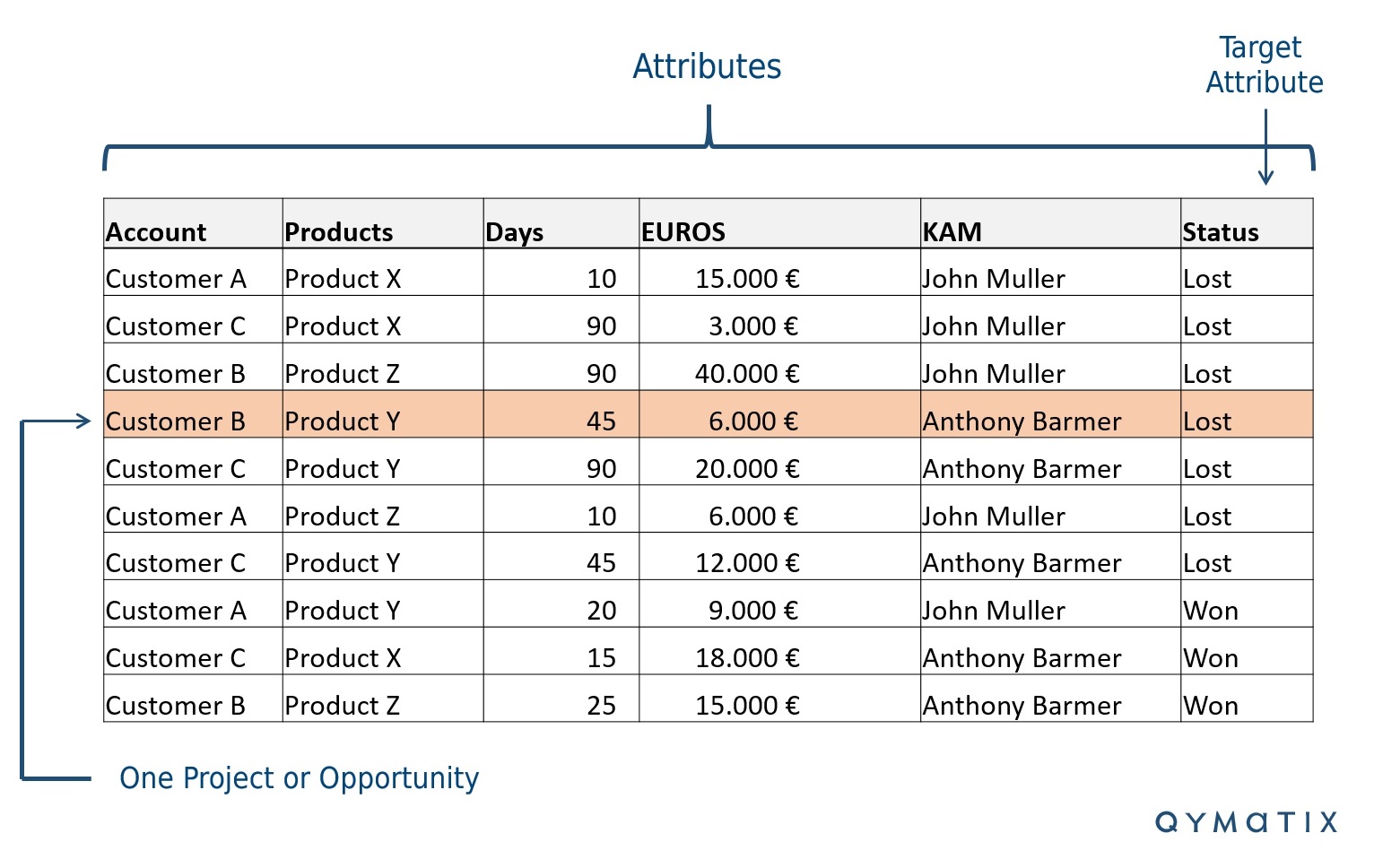
Wahrscheinlich haben Sie nicht genau die gleichen „Attribute“ oder Spaltennamen. Verwenden Sie dieses Beispiel nur als Vorlage oder Modell.
Wir definieren das Problem als „überwacht“, weil wir ein Zielattribut vorhersagen wollen. Es ist ein Klassifizierungsproblem (anstelle beispielsweise einer Regression), weil das Ziel (was wir wissen wollen) eine Kategorie (ja oder nein / gewonnen oder verloren) anstelle einer Zahl ist.
[bctt tweet=“Überwachte Segmentierung ist ein grundlegendes Konzept des Data Mining. „]
Wie aktivieren Sie Ihre Datenanalyse in Excel? Der erste Schritt, bereiten Sie Ihre Daten vor.
Bevor wir mit unserer Prognose in Excel fortfahren, müssen wir kurz die Datenqualität und Konsistenz diskutieren.
Wie bei jedem Data Mining-Projekt müssen Sie Ihre Daten bereinigen und vorbereiten. Im Rückblick auf das obige Excel-Beispiel besteht Ihre Aufgabe als Manager darin, sicherzustellen, dass Ihr Vertriebsteam alle Zellen konsistent füllt.
In diesem Schritt müssen Sie Annahmen treffen und Kompromisse finden. Sie können sogar entscheiden, die Verkaufschancen, die außerhalb eines „normalen“ Bereichs liegen, aus der Analyse herauszulassen. Sie betrachten diese als „Ausreißer“ oder unzuverlässige Daten.
Für den Typ von Predictive Analytics Methode, die wir hier diskutieren, stellen Sie sicher, dass Sie alle Attribute in Klassen oder Gruppen aufteilen. D.h. Sie müssen zuerst numerische Attribute klassifizieren.
Wenn Sie beispielsweise unser Bild oben erneut anschauen, sind die Attribute „Tage“ (wie alt eine Opportunity ist – ihr Lebenszyklus) und „Euro“ (das Verkaufspotenzial oder Ihr Verkaufsziel für diesen Lead) numerisch. Machen Sie diese zu Klassen (oder Gruppen).
Sie werden nur die Attribute klassifizieren, die Sie vorhersagen möchten – um zu erkennen, wie viele Information sie enthalten. Eine einfache Methode besteht darin, die Bereiche in drei oder vier Klassen aufzuteilen. Im Fall des Lebenszyklus können Sie beispielsweise Leads, die weniger als 30 Tage alt sind, zwischen 30 und 60 Tagen und solche, die älter als 60 Tage sind, gruppieren. Jede Opportunity sollte nur einer Klasse angehören. Vermeiden Sie zu viele Klassen – drei bis vier werden reichen. Sonst „Overfitten“ Sie Ihr Modell.
Gehen wir zurück zu unserem Excel-Beispiel, fügen Sie nun Spalten für jede Klasse hinzu, wie im folgenden Bild dargestellt.
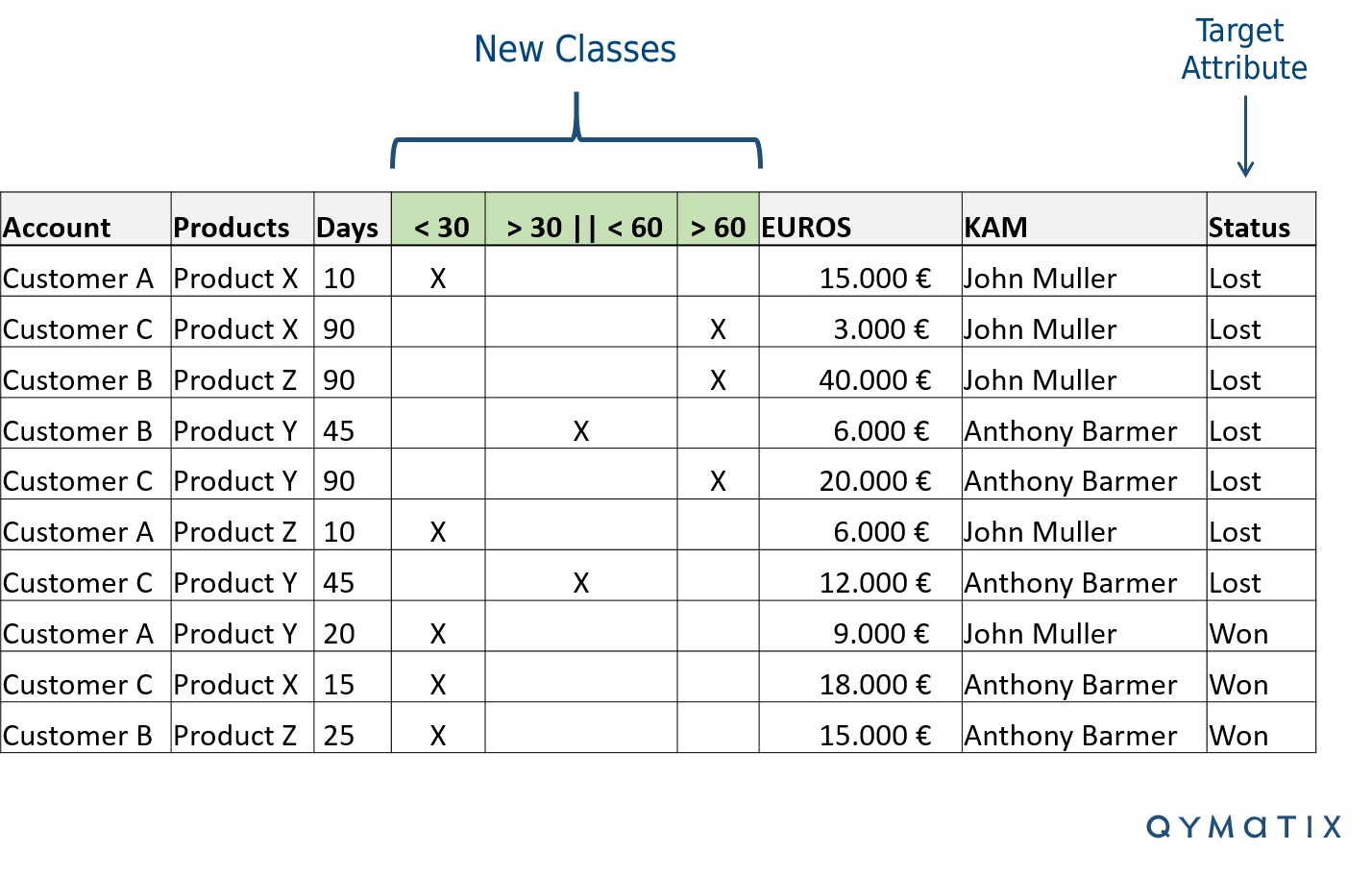
Data Mining-Techniken für den Vertrieb: Qualifizierung von Leads und Verkaufschancen.
Wir haben jetzt ein typisches Klassifizierungsproblem. Wir haben ein Zielattribut (Status – Chance gewonnen oder verloren) und verschiedene informative Attribute definiert. Wir haben unsere Daten bereinigt und strukturiert. Wir haben neue informative Klassen für numerische Attribute erstellt, z. B. Lebensdauer oder Dauer jeder Verkaufschance.
Unsere grundlegende Frage lautet nun: Welche dieser informativen Eigenschaften oder Attribute ist am besten geeignet, unsere Pipeline zu segmentieren, so dass wir erfolgreiche Leads und keine hoffnungslosen vorhersagen können?
Glücklicherweise können wir bei Klassifizierungsproblemen diese Frage beantworten, indem wir eine Formel erstellen. Dieser Algorithmus bewertet, wie gut jedes Attribut unsere Pipeline bezüglich unserer ausgewählten Zielvariablen segmentiert.
Hier stellen wir jetzt ein wichtiges Data-Mining-Konzept vor: Entropie. Die Entropie ist ein Maß für die Unordnung (oder Unreinheit) pro Attribut eines gegebenen Datensatzes. Ähnlich ist die Entropie ein Maß für den mittleren Informationsgehalt pro Zeichen einer Quelle (mehr dazu später), die ein System oder eine Informationsfolge darstellt.
Datenwissenschaftler definieren die Entropie als:
entropy = – p1 log (p1) – p2 log (p2) – …
Der angewendete Logarithmus „log“ ist zur Basis zwei. Jedes p ist der relative Prozentsatz der Eigenschaft innerhalb des Satzes – seine Wahrscheinlichkeit. In unserem Beispiel sind von den zehn Verkaufsmöglichkeiten (Leads) drei für mehr als 60 Tage geöffnet. In diesem Fall beträgt die Wahrscheinlichkeit eines Leads dieser Klasse 30 % (3/10 = 0,30).
In ähnlicher Weise hat die erfolgreiche Akquisition von tatsächlichem Neugeschäft für das Zielattribut 30 % Chancen (3/10 = 0,3). Daher resultiert die Wahrscheinlichkeit, dass aus einem Lead kein Käufer wird, 70%. Jetzt ist die Entropie unserer Pipeline:
entropy (pipeline) = – [0.7 x log(0.7) + 0.3 x log(0.3) ]
= – [0.7 x -0.5 + 0.3 x -1.74 ]
= 0.88
Was Entropie bedeutet, ist nicht einfach zu verstehen. Es ist nur relevant zu wissen, dass Entropie nahe Eins eine „unreine“ Segmentierung darstellt (auf Englisch „impure“) und Entropie nahe Null „reiner“ ist. Mit anderen Worten, wenn Sie nur die Hälfte Ihrer Leads gewinnen, wird Ihre Pipeline eine maximale Entropie von eins haben. Sie haben eine sehr „unordentliche“ Mischung.
Wir haben unser Excel mit Klassen ein wenig umgeordnet. Wir setzen die Zahl „1“ anstelle von „X“, um die Berechnung zu erleichtern. Wir haben die Wahrscheinlichkeit und die Entropie des Zielattributs hinzugefügt. Sie können die Logarithmusbasis 2 mit der Funktion LOG in Excel berechnen. Betrachten Sie dazu das Bild unten.
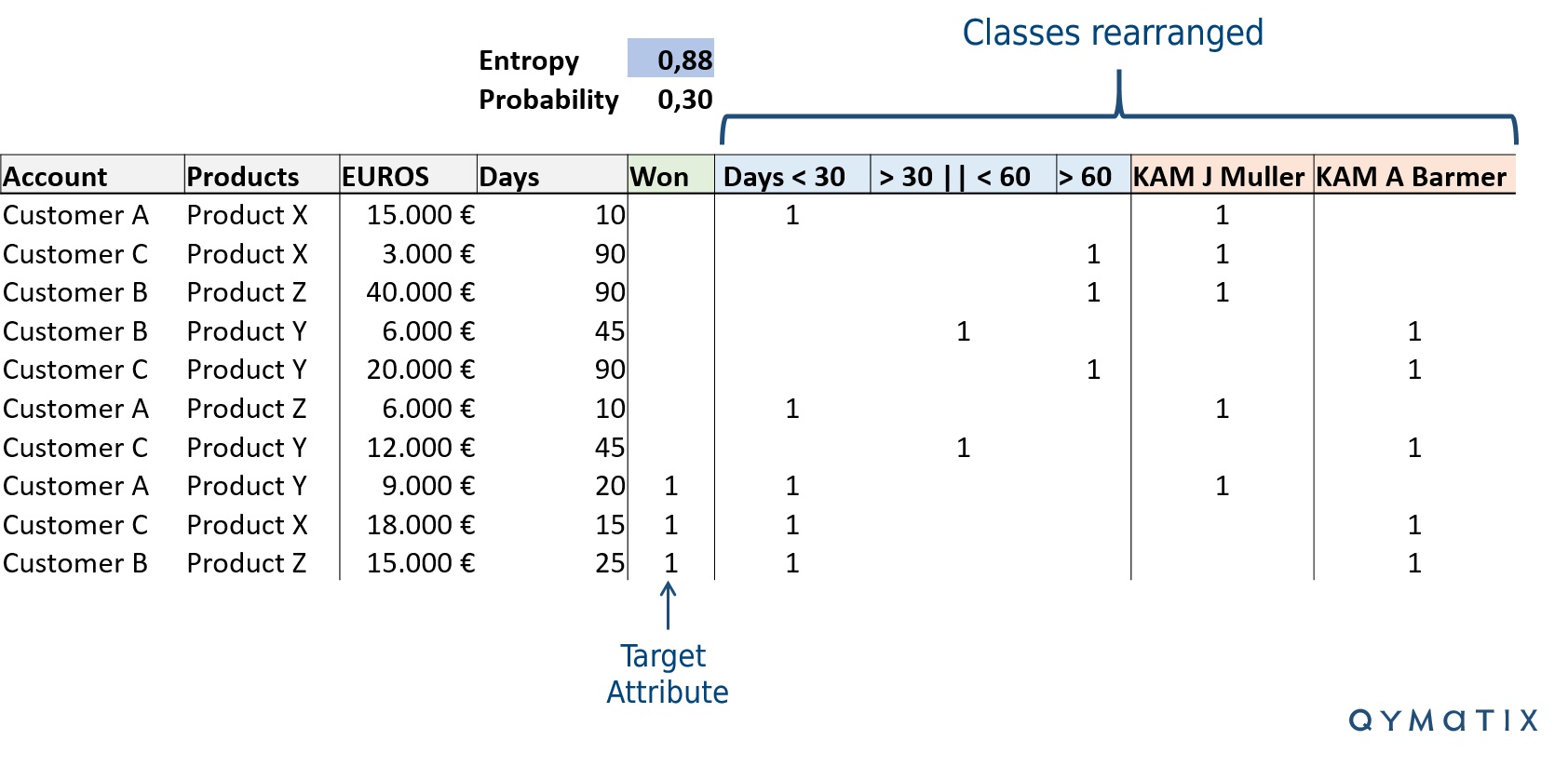
Wie genau funktioniert Predictive Analytics für Ihre Vertriebsplanung? Durch den Informationsgehalt.
Entropie ist nur ein Teil der Geschichte. Wir würden gerne wissen, wie informativ ein Attribut ist, das unser Ziel betrifft – seinen Informationsgehalt. Mit anderen Worten, was ist ein besserer Prädiktor für Vertriebserfolg? Zum Beispiel, wer der Key Account Manager oder wie alt die Verkaufschance ist?
Die Entropie misst, wie „ungeordnet“ ein Datensatz ist. Was wir benötigen ist Information. In der Informationstheorie bezeichnen Datenwissenschaftler Information auch als Maß für die eliminierte Unsicherheit (Wikipedia).
Der Informationsgehalt (IG) misst, um wie viel ein Attribut die Entropie über die gesamte neue Segmentierung, die es erzeugt, verbessert (reduziert).
Jetzt kommt der interessante Fakt. Wenn Sie sich das Bild oben ansehen, werden Sie die zwei neu angeordneten Klassen bemerken: Tage und KAMs. Wir verwenden diese Klassen, um zu berechnen, wie viele Information wir mit jedem Attribut erhalten.
Im Rahmen unserer beaufsichtigten Segmentierung von Verkaufschancen haben wir die gesamte Gruppe z. B. anhand von Tagen und KAMs aufgeteilt.
Wir berechnen den Informationsgehalt jedes Attributs, indem wir die gewichtete Entropie des ausgewählten Attributs von der Entropie der gesamten Pipeline subtrahieren.
Lassen Sie uns ein Beispiel mit der Kategorie „Tage“ machen. Beachten Sie, dass wir für dieses Attribut drei Untergruppen haben, als d1, d2 und d3 angezeigt.
IG (pipeline, attribute) = entropy (pipeline) – [p(d1) x entropy (d1) + p(d2) x entropy (d2) + p(d3) x entropy (d3)]
IG (pipeline, attribute= “days”) = 0.88 – [0.75 x 0.81 + 0.33 x 0.92 + 0.0 x 0.0]
IG (pipeline, attribute= “days”) = 0.06
Wenn wir diese Berechnung wiederholen, indem wir jetzt das Attribut KAM anstelle von Tagen verwenden, erhalten wir eine IG:
IG (pipeline, attribute= “KAM”) = 0.24
Der Informationsgehalt zeigt uns, wie wichtig ein bestimmtes Attribut ist. Denken Sie noch einmal an unsere Frage: Welches Attribut ist informativer?
Jetzt können Sie „KAMs“ beantworten. Nach unserer Berechnung reduziert die Aufteilung der gesamten Pipeline auf die Vertriebsmitarbeiter die Unsicherheit und bietet weitere sinnvolle Informationen. In diesem Beispiel ist es besser zu wissen, wer der Key Account Manager ist, als wie alt jede Opportunity ist. In Predictive Analytics Terminologie wäre das Attribut „KAM“ der bessere Prädiktor.
Data-Mining-Techniken zur Verbesserung des Vertriebs? Lassen Sie die Maschine lernen.
In unserem Beispiel haben wir Excel verwendet, um zu zeigen, dass die Kenntnis, wer der verantwortliche Vertriebsmitarbeiter ist, uns mehr Informationen liefert als das Alter dieser Verkaufschance. Wir haben segmentierte Supervision, Entropie und Informationsgehalt angewendet, um Prädiktoren und Attribute zu klassifizieren.
Diese Data-Mining-Methode bietet wertvolle Informationen bei der Vorhersage, welche Verkaufschance ein Vertriebsleiter pushen oder wo er seine Priorität setzen sollte. Was sind die nächsten Schritte?
Wenn Sie diese Data-Mining-Methode für Ihre CRM- oder ERP-Daten verwenden, können Sie jetzt feststellen, welche Attribute informativer sind. In Bezug auf Predictive Analytics Modeling besteht der nächste Schritt darin, einen „Entscheidungsbaum“ zu erstellen – eine typische Methode des maschinellen Lernens.
Ein Entscheidungsbaum ist ein überspitzter Name für eine Reihe von Unterteilungen, wobei zuerst die Attribute mit mehr Informationen verwendet werden. D.h. Entscheidungsbäume stellen Entscheidungsregeln dar. Die grafische Darstellung als Baumdiagramm veranschaulicht hierarchisch aufeinander folgende Entscheidungen. Ein Bild spricht mehr als tausend Worte. Schauen Sie sich das Untenstehende an.
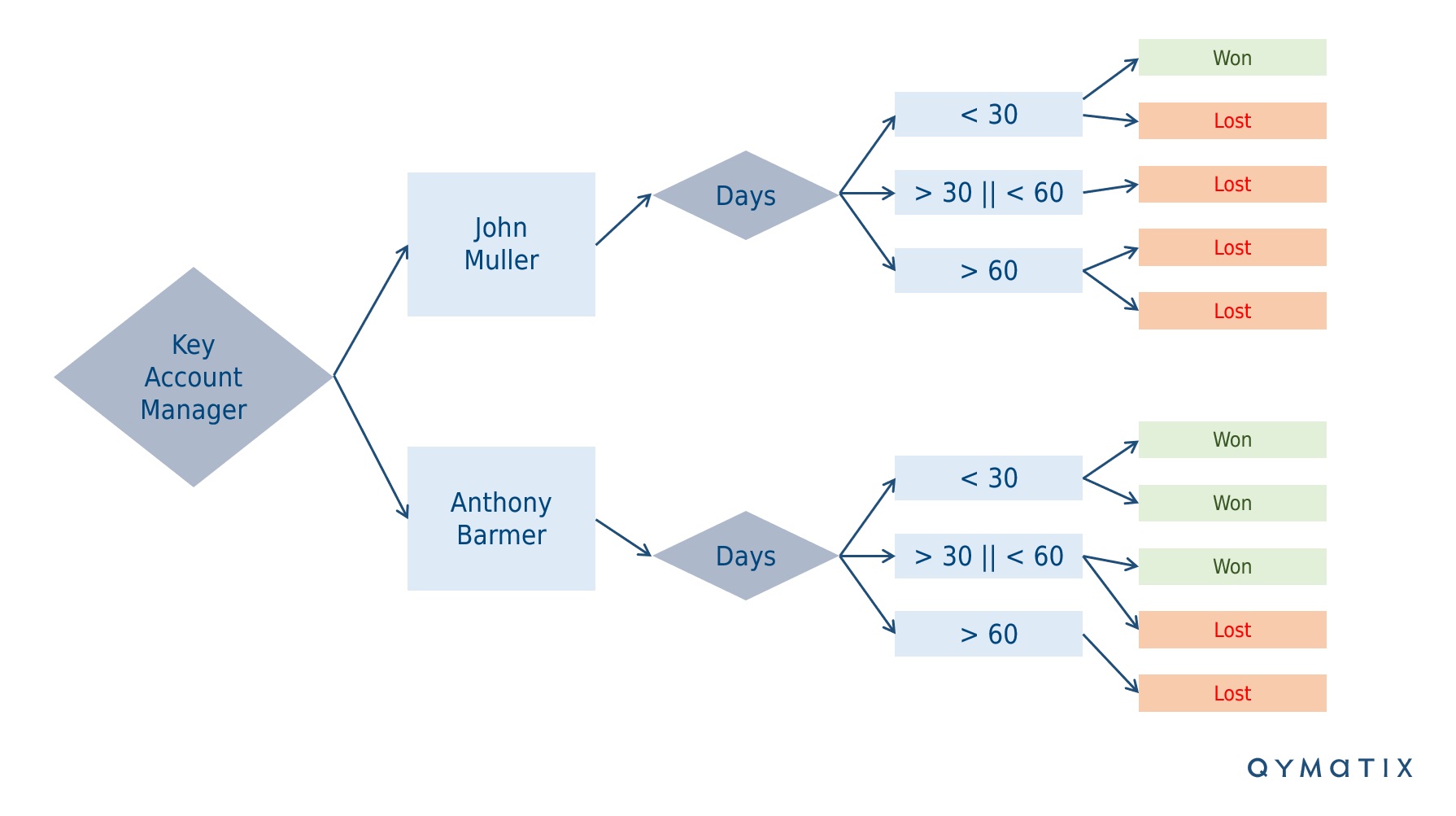
Sie können den Informationsgehalt verwenden, um die Reihenfolge der Attribute in den Wurzelknoten eines Entscheidungsbaums zu berechnen (um einen Entscheidungsbaum mit Excel erstellen) oder die Zuordnung der Entscheidungsregeln.
Überlegen Sie sich schließlich, wie Sie die gewonnenen handlungsrelevante Erkenntnisse visualisieren und die Berechnungen effizient mit Ihrem Vertriebsteam teilen.
Anwendungsbeispiel von Predictive Analytics Methoden für Vertriebsplanung mit einer Excel Vorlage – Fazit
Predictive Analytics beschäftigt sich mit der Anwendung von Data-Mining-Methoden zur Berechnung und Vorhersage der Wahrscheinlichkeit zukünftiger Ergebnisse.
Excel ist eine sehr flexible Software für Predictive Analytics. Mit etwas Zeit und grundlegenden Kenntnissen über Data Mining kann ein Vertriebsleiter z.B. mit Excel seine Pipeline erfolgreich priorisieren. Es gibt natürlich bessere Alternativen zu Excel für Predictive Analytics.
Wir haben in diesem Artikel einige grundlegende Konzepte zur Predictive Analytics vorgestellt: „Entropie“, die verwendet wird, um zu messen, wie „rein“ oder „geordnet“ ein Sortiment ist. „Informationsgehalt“ berechnet die Menge an Information, die von jedem Attribut gegeben wird – in statistischer Hinsicht. Je höher, desto mehr Informationen liefert ein Attribut.
Unter Verwendung der informativeren Attribute kann ein Vertriebsleiter die Leads mit besseren Chancen priorisieren, Preispolitik dynamisch anpassen oder Kundenabwanderung vermeiden.
ICH MÖCHTE PREDICTIVE ANALYTICS FÜR DEN VERTRIEB
Kostenloses eBook zum gratis Download: Predictive Analytics – Was es ist und wie Sie beginnen können
Predictive Analytics: Methoden, Daten und Ideen aus der Praxis
Downloaden Sie jetzt das kostenlose eBook.
Wohin dürfen wir das PDF senden?



Literaturnachweis:
Header Image: Johann Heinrich Wilhelm Tischbein [Public domain], via Wikimedia Commons
{kind=link}