Shakespeare is dead! Let machine learning bring intelligence to your text.

Please enter your Email address
One first-hand example of predictive text scoring and sentiment analytics using machine learning.
We are always looking for a way to bring machine learning to ERP-Systems. Companies can apply a Predictive Scoring using Machine Learning to prioritize sales leads, discover cross-selling opportunities and to classify text.
To support the efforts of our B2B marketing team, we invested time and resources, developing a machine learning scoring system for our blog content.
We believe our experience can be valuable for other B2B marketing teams.
Imagine you work in a content marketing team and would like to predict whether a new article will drive traffic to your company page and will increase conversion. You possess hundreds of past articles that are known to have driven web-traffic, and that brought you valuable sales leads.
You can measure with your web analytics tool, which ones are the articles that bring more traffic and most leads. After that, you will attempt to discover what are the characteristics, keywords, and paragraphs that brought your success.
We trained our model using text from our blog, although you can apply this example to other text-sentiment analytics, such as social media, sales reporting and marketing emails. We used AutoML from Google, but you can use another machine learning provider.
We trained our model using text from our blog.
Let’s review together some basic concepts about machine learning, text sentiment classification and then presenting the results of our example.
Why is Machine Learning (ML) the right tool for text analytics and lead scoring?
Classical programming, like standard lead scoring, requires the software developer to specify step-by-step instructions and rules to the computer. Although this methodology works in relatively simple cases, the variations and complexity in unstructured data, such as text, make it hard to imagine where to begin. Luckily, machine learning software can learn from the data and efficiently solve this problem.
Text Analytics and Lead Scoring are, from the data structure perspective, dissimilar. The former works with unstructured data, the latter with (usually) structured data. There are, from the machine learning point; however, some similarities.
For both predictive analytics methods an algorithm, usually a random forest predictor, will score or classify elements based on pre-labelled positive ones. For example, in the application we are describing here, we had pre-selected the blog posts with the highest sentiment score.
How did we build our machine learning text predictor, what tools and data did we use?
Machine learning involves employing data to train algorithms to achieve the desired outcome. Using google analytics, we pre-classified almost 200 articles from our blog into four categories or sentiment, from 0 to 3 — the higher the sentiment, the better the item. We defined “better” by looking at three variables: number of organic readers, bounce rate and proportion of visitors that sent a request for contact. We weighted the categories.
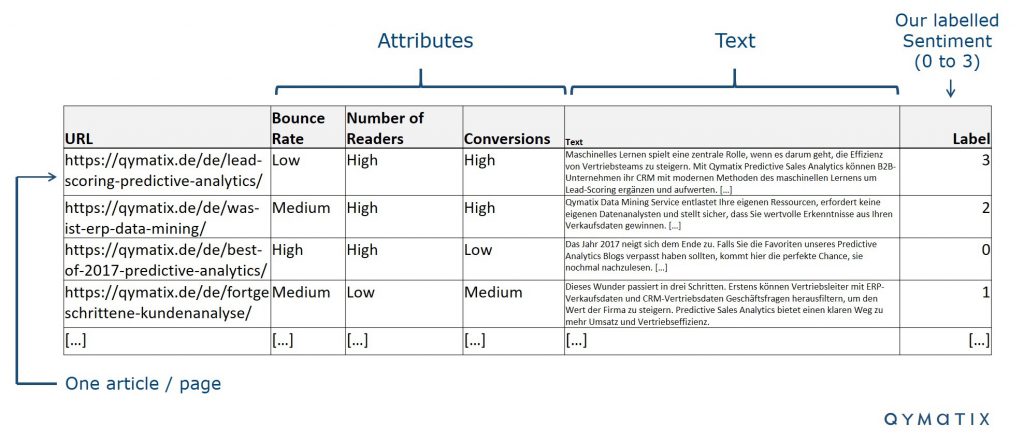
The first step is sourcing the data. The cheapest and most reliable source of data is, of course, our blog itself. Using the data that a company already possess is the most sensible first step in almost any machine learning project.
Data preparation is the second and maybe most critical aspect of any machine learning project. To train the model, we need to provide the labelled data, together with the sentiment or score we want the model to predict.
In the image above, we presented an extract of the database we use. We listed all the URLs from our blog (for German entry only). We scrapped the text of each input (scrapping means: with the URL the corresponding text was automatically inserted into the database) and labelled them from 0 to 1.
Now comes the magic. How to use unstructured data (text from the articles) to predict how successful the next article will be? Using supervised machine learning, we trained a model to recognize the patterns and content we labelled as sentiment 3 (our most successful items). There should be an even distribution of labels, and you need a minimum number of elements in each tag, say ten articles per sentiment. To capture roughly similar amounts of training examples for each category, we split the 200 entry into almost four evenly distributed categories (around 50 each). Below you can see the confusion matrix resulting from our training.
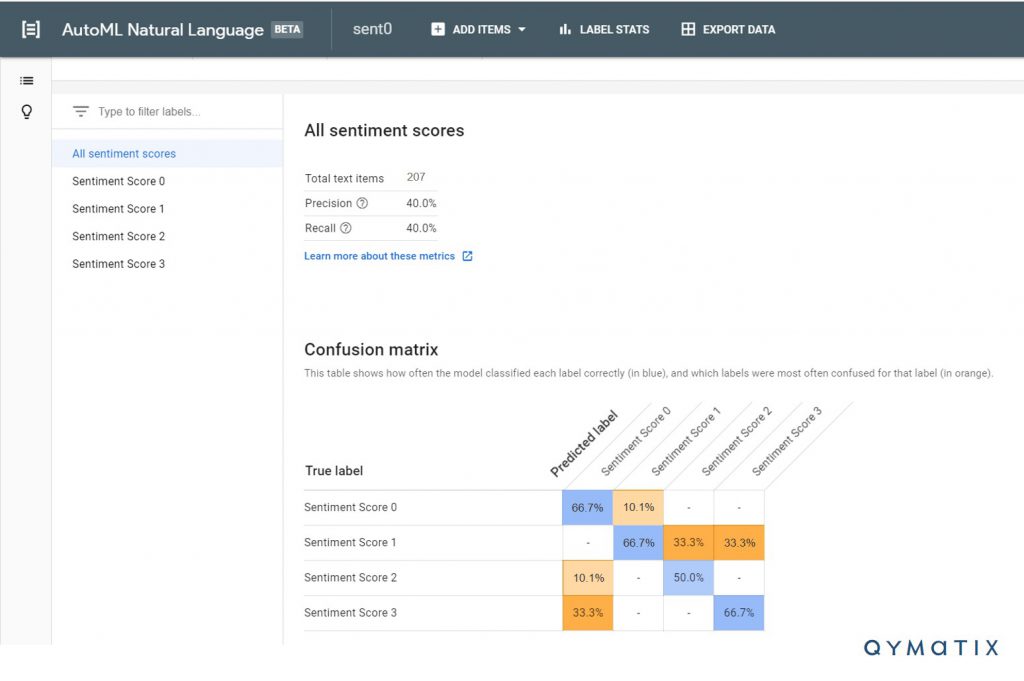
What did we learn from this application of machine learning, and for what can we use it?
We learnt three lessons. First, we had more data than we thought. Second, that with the right tool, one can use the data at hand to support better decisions. Third, machine learning for marketing and text sentiment analysis is fun.
Now let’s come to its application. We can basically “propose” a text to our newly trained machine learning model, and it tells us how successful it could be, by predicting its sentiment, from 0 to 3. We fed it with text from public sales magazines and got a short-list of articles and topics that could yield us better results. Below you can see an example of how it works.
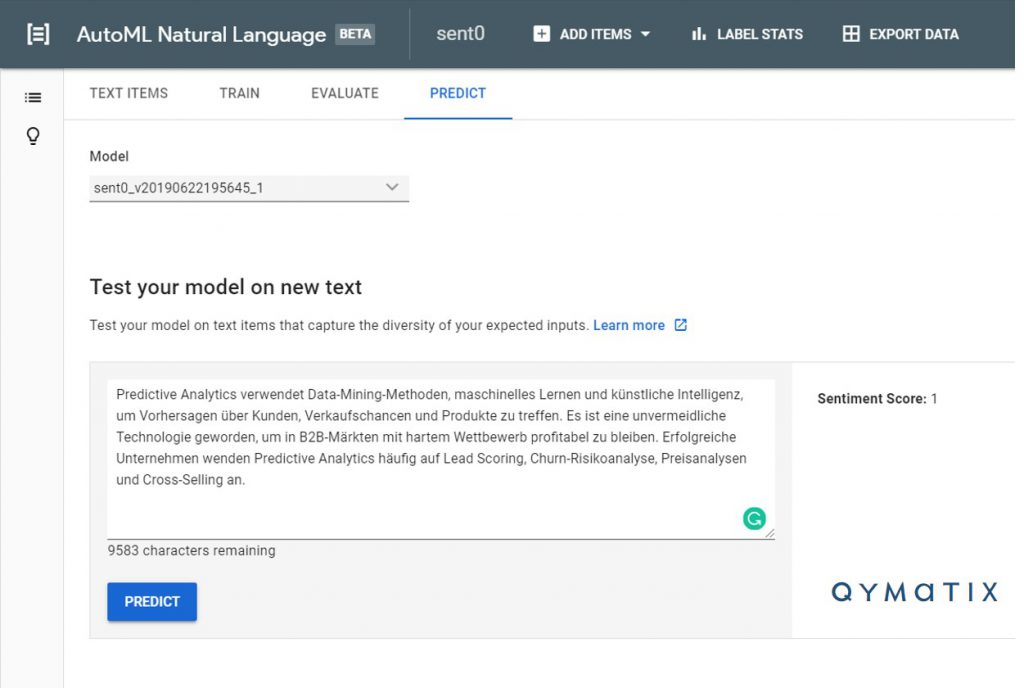
Do we use this model to write the texts in our articles autonomously? Of course not. We only use it to support our decisions regarding content and keywords.
We also re-apply a couple of steps on how to get started with predictive analytics. These steps are:
>> Select your business goal
>> Use the data that it is closest to your goal
>> Select and train a model
>> Apply the insights to improve your decisions
We are confident these steps can be useful for companies looking to get started with predictive analytics using machine learning.
CALCULATE NOW THE ROI OF QYMATIX PREDICTIVE SALES SOFTWARE
Example of predictive text scoring and sentiment analytics using machine learning – summary.
Imagine you are a marketing manager aiming to create articles that will drive engagement and new leads. Alternatively, imagine you are a sales manager writing hundreds of emails per week and would like to know which the ones with higher response are. Gaining insights from vast amounts of unstructured data, such as text, is an impossible challenge for a human.
Machine Learning is the right tool for text analytics. We trained in this example, a text sentiment algorithm to classify the articles that should drive higher engagement in our blog. Machine learning, an example of narrow artificial intelligence, can also be used to further application in B2B sales and marketing, such as lead scoring, churn attrition and prevention and pricing analytics.
To our machine learning text predictor, we used AutoML from google, although other tools are available. First, we pre-labelled almost 200 pieces of content, pages and posts, based on the level of engagement they have driven. We then trained the model and checked its performance using a confusion matrix. We finally used our model to predict new pieces of text.
We learnt from this application of machine learning that if you know how there are easy ways to get started to predictive analytics. We used the data we already had, and we are using the insights to improve our future articles.
Do you have any further questions on this topic? We are happy to help!
CONTACT US TODAY FOR YOUR PERSONAL CALL
Free eBook for download: How To Get Started With Predictive Sales Analytics – Methods, data and practical ideas
Predictive analytics is the technology that enables a look into the future. What data do you need? How do you get started with predictive analytics? What methods can you use?
Download the free eBook now.
Please enter your Email address


- We will use this data only to contact you for discussing predictive sales KPIs. You can read here our declaration on data protection.
